Image Reader (OCR)
插件截图
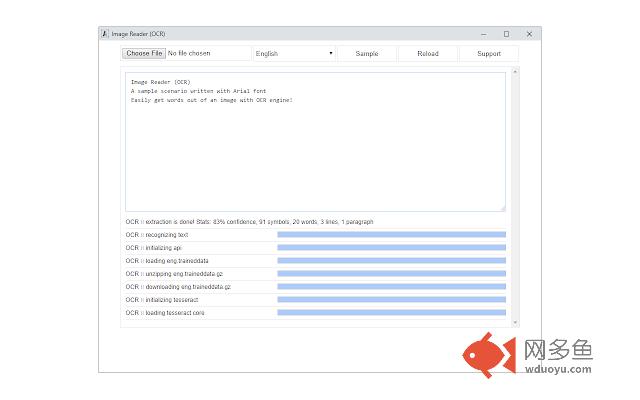
插件概述
Easily get words out of an image with OCR engine!插件详情
Image Reader (OCR) extension help you easily get words out of any image. It uses an open-source OCR library called Tesseract.Tesseract.js is an open-source JavaScript library and is made via an Emscripten port of the famous Tesseract OCR Engine written in C and C++. Please visit (https://github.com/naptha/tesseract.js) to get more info.
In order to work with this add-on, simply open the add-on's UI and load your image via the file selector (top left corner). A sample scenario is also included in the package to test the add-on (press on the "sample" button at the top toolbar). Before using the add-on, please make sure to select the appropriate OCR language. Default OCR language is set to English.
Note: this add-on uses: "https://github.com/naptha/tessdata/tree/gh-pages/3.02"
GitHub repo in order to fetch language data required for the OCR operation. Language data packs are very large in size and cannot be included in the add-on’s package.
In order to report bugs, please fill the bug report form in the extension's homepage (http://mybrowseraddon.com/image-reader.html).
其他信息
官方唯一标识:cakcfoce****************hflfbhmf
官方最后更新日期:2019年3月30日
分类:生产工具
大小:838KiB
版本:0.1.2
语言:English
提供方:none
星级:5
插件下载
| 下载链接一 下载链接二 |
| Chrome插件离线安装教程 |
温馨提示
本站中的部份内容来源网络和网友发布,纯属个人收集并供大家交流学习参考之用,版权归版权原作者所有。
如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
如果您觉得网多鱼对您有帮助,欢迎收藏我们 Ctrl+D。